Proyecto UTN FRSN NEWS
¿Qué es?
Es un proyecto personal para practicar procesos robustos de web scraping y automatización, uso colas de tareas, bases de datos SQL y aprender sobre Cloudflare Workers y su ecosistema de herramientas.
¿Cómo funciona?
El proyecto se compone de varios scripts que se encargan de extraer y publicar las últimas noticias de la facultad en un canal de Telegram.
¿Cuál es la fuente?
La fuente de las noticias es el sitio web oficial de la Facultad Regional San Nicolás de la Universidad Tecnológica Nacional, específicamente la sección de noticias que se encuentra en el siguiente enlace: https://www.frsn.utn.edu.ar/?paged=1&page_id=80
¿Dónde puedo verlo?
En el canal de Telegram: https://t.me/utnfrsnnews
¿Qué tecnologías utiliza?
Utiliza Cloudflare Workers para alojar los scripts, Cloudflare D1 como base de datos SQL, Cloudflare Queues para gestionar las tareas y Cloudflare Images para almacenar las imágenes de las noticias.
¿Cómo está estructurado el proyecto?
El proyecto se compone de cuatro aplicaciones principales: el Index Scraper, el Main Scraper, el Messenger y la Webpage. Cada una de ellas tiene una función específica en el proceso de extracción y publicación de las noticias.
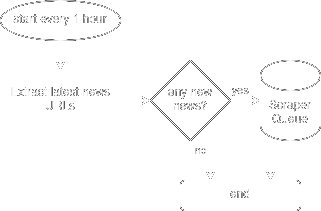
Index Scraper
Detecta noticias nuevas y extrae las URLs de las mismas
Corre a los 0 minutos de cada hora.
El workflow del mismo consiste en, primero, traer la URL de la última noticia que tengamos disponible en la base de datos, en caso de ser la primer corrida no va a traer ninguna y se almacena None.
Luego, obtiene las últimas noticias de la facultad, las parsea y se fija si en alguna de las primeras 5 más recientes encuentra la URL de la base de datos.
De ser así, corta en ese punto y filtra todas las noticias que
ya existan en la DB. Si luego de filtrar, quedan noticias, insertar
todas las URLs que encontró en esa página (en orden cronológico
ascendente) en la cola
utn-frsn-news-scraper
para que el Main Scraper las procese y recupere la información
completa de las mismas.
En caso de que la última noticia de la DB no se encuentre en las primeras 5 noticias, se continúa con las 4 páginas siguientes y se hace el mismo análisis pero esta vez de todo el listado de noticias excepto las 5 más viejas (ya que para asegurarnos que no hubo ningún hueco en la publicación de noticias hecho por el origen, asumimos que el publicar noticias previas a la última es una posibilidad de caso límite, y ponemos como margen que pueden llegar a publicar una noticas 5 lugares atrás de la(s) más reciente(s)).
Si corta en algún momento, hace el mismo análisis mencionado,
filtra todas las URLs de noticias que ya estén en la DB y
agrega las nuevas a la cola
utn-frsn-news-scraper.
En caso de no cortar, continúa trayendo lotes de 5 páginas hasta la última página de resultados de noticias, y ahí es cuando hace el corte definitivo y procede al filtrado e inserción en la cola.
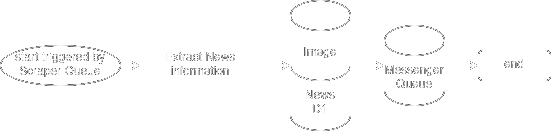
Main Scraper
Extrae la información completa de cada noticia a partir de su URL
Corre una única instancia a la vez, y es disparado por la cola
utn-frsn-news-scraper.
Cloudflare, si hay tareas en la cola, levanta un solo worker para que procese todas las tareas pendientes. Está en la decisión del desarrollador si procesarlas secuencialmente o paralelamente, lo cual es una gran ventaja ya que este proyecto depende de ser secuencial en el orden en que las noticias se guardan y se publican.
Al finalizar el scraping, guarda la imagen de la noticia en Cloudflare Images y almacena toda la información de la noticia en la DB SQL (Cloudflare D1).
Por último, inserta una tarea en la cola de trabajo
utn-frsn-news-messenger
para que el Messenger envíe la noticia por Telegram.
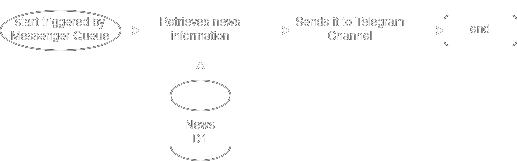
Messenger
Envía la noticia por Telegram
Corre una única instancia a la vez, y es disparado por la cola
utn-frsn-news-messenger.
Al igual que el workflow anterior, Cloudflare levanta un solo worker para que procese todas las tareas pendientes de la cola de trabajo. Lo cual es muy conveniente para procesar secuencialmente cada tarea pendiente de enviar mensajes y enviar las noticias en el orden cronológico correcto por Telegram.
El workflow de esta aplicación es muy sencillo, para cada tarea levanta la información de la DB del ID de la noticia a enviar, formatea el mensaje y lo envía por Telegram. Envía primero la imagen de la noticia, luego envía el título y el contenido de la noticia en un mensaje aparte. Esto se realiza de esta manera porque el "caption" de la imagen en Telegram tiene un límite de caracteres relativamente bajo comparado a la cantidad de caracteres que contiene el contenido de cada noticia. Incluso, hay veces que las noticias superan el propio límite de caracteres de un mensaje de texto de Telegram, por lo que se hace un corte cada cierta cantidad de caracteres para enviar el contenido en varios mensajes, y así evitar perder información de la noticia. Podemos decir con seguridad que esto pasa muy cada tanto, y a lo sumo se tiene que enviar el contenido en dos mensajes.
¿Cómo es la estructura de la base de datos?
La base de datos se compone de una sola tabla llamada "news" que almacena toda la información relacionada con cada noticia, incluyendo su URL, título, contenido, fecha de creación, entre otros campos.
| Campo | Tipo | Descripción |
|---|---|---|
| id | INTEGER | Identificador único de cada noticia |
| url | VARCHAR(511) | URL única que identifica esta noticia |
| title | VARCHAR(511) | Título de la noticia |
| content | TEXT | Contenido de la noticia |
| photo_id | VARCHAR(36) | ID de la imagen en Cloudflare Images |
| response_elapsed_seconds | REAL | Segundos que tardó el servidor de la facultad en completar la solicitud HTTP |
| parse_elapsed_seconds | REAL | Segundos que tardó en parsear el HTML |
| origin_created_at | TEXT | Fecha y hora de creación de la noticia por el origen |
| indexed_at | TEXT | Momento en que el Index Scraper detectó esta noticia |
| inserted_at | TEXT | Momento en que el Main Scraper insertó esta noticia |
¿Cómo es la estructura de las colas de trabajo?
El proyecto utiliza dos colas de trabajo para gestionar las tareas de scraping y envío de mensajes por Telegram.
La primera cola, llamada
utn-frsn-news-scraper,
se encarga de almacenar las URLs de las noticias que el Index Scraper
detecta como nuevas y que el Main Scraper debe procesar para extraer la
información completa de cada noticia.
| Campo | Tipo | Descripción |
|---|---|---|
| news_url | string | URL de la noticia a procesar |
| photo_url | string | URL de la foto de la noticia a procesar |
| inserted_at | string | Fecha de inserción de la tarea en la cola (fecha de indexado de la noticia) |
La segunda cola, llamada
utn-frsn-news-messenger,
se encarga de almacenar los IDs de las noticias que el Main Scraper ha
procesado y que el Messenger debe enviar por Telegram.
| Campo | Tipo | Descripción |
|---|---|---|
| news_id | integer | ID interno de la noticia a procesar |
| inserted_at | string | Fecha de inserción de la tarea en la cola (fecha de insertado de la noticia) |
¿Qué infraestructura se usa?
En la actualidad, todo el proyecto (es decir, las 4 apps) se encuentra alojado en Cloudflare Workers, utilizando Cloudflare D1 como base de datos SQL, Cloudflare Queues para gestionar las tareas y Cloudflare Images para almacenar las imágenes de las noticias.
Se utiliza el plan de pago Workers Paid y el plan de 100k Images (también pago).
El listado de servicios y su documentación es la siguiente:
- Cloudflare Workers: https://workers.cloudflare.com/
- Cloudflare D1 (main database): https://developers.cloudflare.com/d1/
- Cloudflare Images: https://developers.cloudflare.com/images/
- Cloudflare Queues: https://developers.cloudflare.com/queues/
¿Siempre se usó la misma infraestructura?
No, el proyecto tuvo varias migraciones de infraestructura hasta llegar a la actual en Cloudflare Workers. Esto se debió a varios factores, como cambios en los planes gratuitos de los servicios utilizados, la necesidad de una mayor robustez y disponibilidad, y la búsqueda de una mejor integración entre las herramientas utilizadas.
Primero se comenzó con Heroku y MongoDB Atlas, luego se migró a GCP (y se mantuvo MongoDB Atlas) y finalmente a Cloudflare Workers.
De cada una de esas etapas he aprendido mucho y de las migraciones aprendí más todavía.
Heroku
Lo que puedo contar de Heroku es que fue una buena plataforma para comenzar, especialmente por su facilidad de uso y su ecosistema de herramientas (en su momento las que usé eran gratuitas).
Se utilizaba Scheduler y Task para programar y ejecutar las aplicaciones de scraping y mensajeo/notificación.
Repositorio del proyecto en el momento que se usaba HerokuGoogle Cloud Platform (GCP)
Al momento de migrar, GCP resolvía todas las necesidades del proyecto y tenía un free tier bastante generoso para lo que se necesitaba.
Se utilizó el servicio Pub/Sub para crear tópicos y suscribir a los mismos las aplicaciones (Index Scraper, Main Scraper y Messenger)
Cloud Schedule se usaba para programar el insertado de un mensaje en el tópico que levantaba la instancia del Index Scraper.
Cloud Functions se encargaba de instanciar las aplicaciones (Index Scraper, Main Scraper y Messenger) al recibir un mensaje en el tópico correspondiente.
Seguimos utilizando MongoDB como base de datos principal y para guardar los registros y resultados de las colas de trabajo. Utilizar SQL en GCP era demasiado caro para el uso que le íbamos a dar, por lo que se mantuvo el free tier de MongoDB Atlas.
La gestión de los servicios se hacían principalmente mediante scripts de Shell, y también ayudaba mucho la plataforma Console de GCP.
Repositorio del proyecto en el momento que se usaba GCPCloudflare
Lo que usamos hoy en día en Cloudflare fue explicado en el apartado anterior.
En este nueva infra se hicieron dos grandes pasos, el primero fue que se comenzó a utilizar como base de datos principal Cloudflare D1 en lugar de MongoDB Atlas. Esto se debió a que D1 ofrece una solución SQL integrada con el ecosistema de Cloudflare Workers, lo que simplifica la gestión y el desarrollo del proyecto, y además tiene un free tier bastante generoso.
Lo segundo fue que se hosteó una aplicación full-stack web para mostrar las noticias en una página web sencilla, utilizando FastAPI en el backend y Jinja2+TailwindCSS para el renderizado de plantillas.
Todo esto está montado en una de las redes más grandes y robustas del mundo, con una infraestructura altamente disponible y escalable.
Los servicios son configurables mediante un JSON dentro del proyecto
llamado wrangler.jsonc,
lo que facilita la gestión y el despliegue de las aplicaciones.
El despliegue es muy sencillo, con un solo comando
uv run pywrangler deploy
o mejor aún con el deploy automático mediante GitHub Actions
(el cual está configurado en el repositorio).
Apenas comencé con la migración del código, me encontré que promueven el uso de uv para gestionar los proyectos de Python en Workers, y la verdad es que es una herramienta fantástica que facilita mucho la vida del desarrollador.
Aún así, la migración de GCP a Cloudflare fue un gran desafío, tanto como para refactorizar gran parte del código, para ser asíncrono y utlizar Pyodide (ya que Cloudflare Workers no soporta Python de forma nativa, sino que utiliza WebAssembly mediante Pyodide), como también para transferir toda la información de MongoDB Atlas a Cloudflare D1 (SQL).
Todo este gran desafío que llevó unos 3 días de mucho esfuerzo y aprendizaje quedó documentado en el Github Issue #3 del repositorio:
Refactor + Migración de GCP a Cloudflare Workers¿Dónde puedo ver el código fuente?
El código fuente del proyecto está disponible en GitHub en el siguiente enlace:
Repositorio del proyecto¿Quién lo desarrolló?

El proyecto fue desarrollado por Goran Prpic, un desarrollador argentino apasionado por la tecnología y el aprendizaje continuo.
Puedes contactarme o ver más de mis proyectos en los siguientes enlaces:
- GitHub: https://github.com/gorandp
- Linkedin: https://linkedin.com/in/gorandp
- Telegram: https://t.me/gorandp